HashMap
HashMap
Hash函数是指把⼀个⼤范围映射到⼀个⼩范围。把⼤范围映射到⼀个⼩范围的⽬的往往是为了 节省空间,使得数据容易保存。
HashMap扩容机制
1 | int threshold; // 所能容纳的key-value对极限 |
Node[] table的初始化长度length(默认值是16),Load factor为负载因子(默认值是0.75),threshold是HashMap所能容纳的最大数据量的Node(键值对)个数。threshold = length * Load factor。也就是说,在数组定义好长度之后,负载因子越大,所能容纳的键值对个数越多。
map初始化为一个长度为2的数组,loadFactor=0.75,threshold=2*0.75=1,也就是说当put第二个key的时候,map就需要进行resize。
https://tech.meituan.com/2016/06/24/java-hashmap.html
HashMap和HashTable的区别
- HashTable是线程安全的
- HashTable key不能为空,HashMap可以.存在数组为0的位置
HashMap的实现原理 HashMap数据结构?
JDK1.7 Table数组+ Entry链表
JDK1.8 Table数组+ Entry链表/红黑树( 为什么用红黑树)
红黑树有自平衡的特点,可以防止不平衡情况的发生,所以可以始终将查找的时间复杂度控制在 O(log(n))
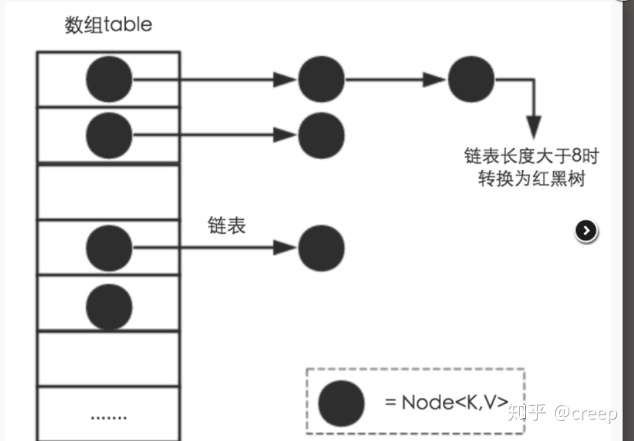
HashMap采用Entry数组存放key-value,每个 key value组成一个实体,Entry类实际上是一个单向的链表结构,它有next指针指向下一 个实体, 1.8中链表大于8时会转成红黑树.长度降到 6 就转换回去.
HashMap源码理解
HashMap如何
put数据(从HashMap源码角度讲解)?
对key的Dashcode()做hash运算,计算index.
如果没碰撞直接放到bucket⾥
如果碰撞了,以链表的形式存在buckets后
如果节点已经存在就替换old value(保证key的唯⼀性)
如果bucket满了(超过load factor*current capacity),就要resize
get数据
对key的hashCode()做hash运算,计算index;
如果在bucket⾥的第⼀个节点⾥直接命中,则直接返回;
如果有冲突,则通过key.equals(k)去查找对应的Entry;分为下面两种方式.
若为树,则在树中通过key.equals(k)查找,O(logn);
若为链表,则在链表中通过key.equals(k)查找,O(n)。
HashMap怎么手写实现?
https://www.jianshu.com/p/985534b21089
HashTable实现原理
ConcurrentHashMap的实现原理
HashTable ConcurrentHashMap 区别
Hashtable的实现是基于Dictionary抽象类的。Java5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
https://www.bilibili.com/video/BV1kJ411C7hC?p=9&spm_id_from=pageDriver
TreeMap具体实现
TreeMap是一个有序的key-value集合,是非线程安全的,基于红黑树(Red-Black tree)实现。其映射根据键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。其基本操作 containsKey、get、put 和 remove 的时间复杂度是 log(n) 。TreeMap是非同步的。 它的iterator 方法返回的迭代器是fail-fastl的。
https://www.cnblogs.com/nananana/p/10426377.html
HashMap与HashSet的区别
基于 HashMap 实现的,底层采用 HashMap 来保存元素
HashSet实现了Set接口,它不允许集合中有重复的值
HashSet与HashMap怎么判断集合元素重复?
l nn为什么不一开始就使用红黑树
因为红⿊树需要进⾏左旋,右旋,变⾊这些操作来保持平衡,⽽单链表不需要。
当元素⼩于8个当时候,此时做查询操作,链表结构已经能保证查询性能。
当元素⼤于8个的时候,此时需要红⿊树来加快查 询速度,但是新增节点的效率变慢了。
因此,如果⼀开始就⽤红⿊树结构,元素太少,新增效率⼜⽐较慢,⽆疑这是浪费性能的。
什么时候退化为链表
为6的时候退转为链表。中间有个差值7可以防⽌链表和树之间频繁的转换。
假设⼀下,如果设计成链表个数超过8则链表转 换成树结构,链表个数⼩于8则树结构转换成链表,
如果⼀个HashMap不停的插⼊、删除元素,链表个数在8左右徘徊,就会 频繁的发⽣树转链表、链表转树,效率会很低。
https://www.youtube.com/watch?v=jwL1W8zEuX4
https://www.bilibili.com/video/BV1if4y167eE?p=4
https://zhuanlan.zhihu.com/p/127147909
https://zhuanlan.zhihu.com/p/348756860
ArrayMap
ArrayMap类有两个非常重要的静态成员变量mBaseCache和mTwiceBaseCacheSize,用于ArrayMap所在进程的全局缓存功能:
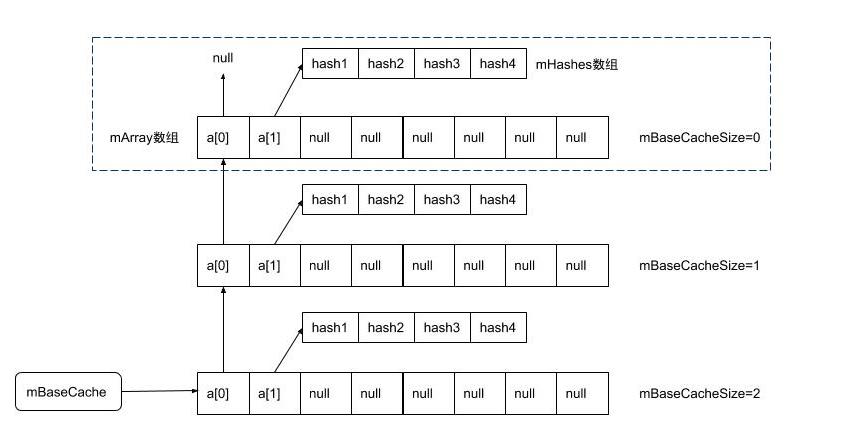
传入ArrayMap(4) 或者ArrayMap(8),性能会有变化吗
构造方法
1 | public ArrayMap(int capacity, boolean identityHashCode) { // 如果传入一个 capacity =4 |
1 | private void allocArrays(final int size) { |
https://juejin.cn/post/7049631659116888094
http://gaozhipeng.me/posts/arraymap/
http://gityuan.com/2019/01/13/arraymap/
https://www.youtube.com/watch?v=I16lz26WyzQ
https://juejin.cn/post/6844904119098982414
https://juejin.cn/post/6844903762470060045
ArrayMap和HashMap的区别
ArrayMap相比传统的HashMap速度更慢,因为其查找方法是二分法,并且当删除或添加数据时,会对空间重新调整,可以说ArrayMap是牺牲了时间来换空间,ArrayMap与HashMap的区别主要在:
存储方式不同:HashMap内部有一个HashMapEntry<K,V>[ ]对象,而ArrayMap是一个<key,value>映射的数据结构,内部使用两个数组进行数据存储,一个数组记录key的hash值,另一个数组记录value值。
添加数据时扩容的处理不一样:HashMap进行了new操作,重新创建对象,开销很大,而ArrayMap用的是copy数据,效率相对高很多。
ArrayMap提供了数组收缩的功能,在clear或remove之后,会重新收缩数组,释放空间。
ArrayMap采用的是二分法查找。
https://juejin.cn/post/7049631659116888094
SparseArray
key是int类型的Map,Android再次提供效率更高的数据结构SparseArray,可避免自动装箱过程,SparseArray不需要保存key所对应的哈希值,所以比ArrayMap还能再节省1/3的内存。
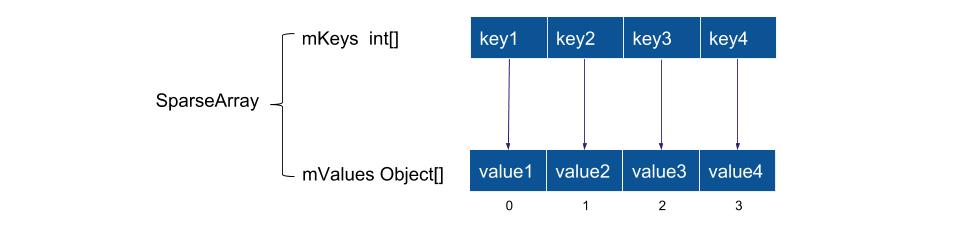
SparseArray构造mKeys mValues两个数组,默认长度10,也可以自己定义initialCapacity
1 | public SparseArray(int initialCapacity) { |
1 | public void put(int key, E value) { |
1 | public void delete(int key) { |
https://blog.csdn.net/zxt0601/article/details/78333328
http://www.jcodecraeer.com/a/anzhuokaifa/2017/0912/8504.html